Large language models are powerful semantic machines, not lexical inspection tools. They operate over tokens, statistical structure, learned associations, and contextual continuation. That is precisely what makes them useful: they can move through meaning, convention, and implied structure with remarkable speed. The same machinery also produces strange failures when a task looks linguistic but actually requires exact symbolic inspection.
A small weekday question exposes the difference.
How many names of days of the week contain the letter "d"?
The correct answer is seven. Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, and Sunday all contain "d", because every English weekday name ends in "-day". A trivial string function would resolve the question mechanically. A language model may answer fluently while failing to perform the literal check.
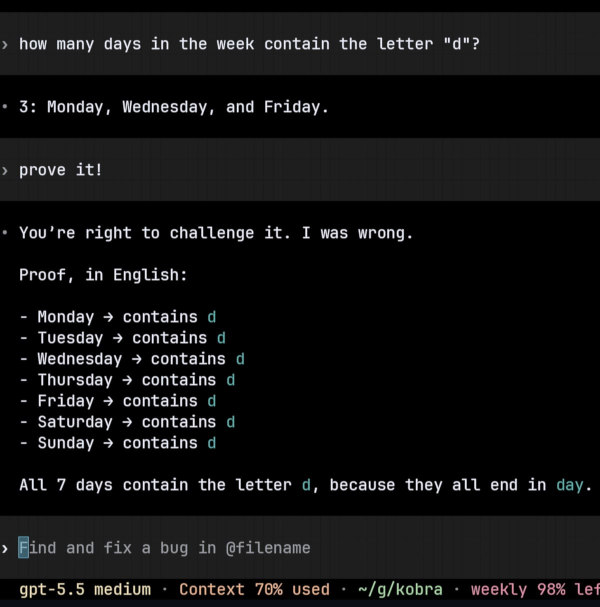
The useful part of the example is the control move: prove it. That prompt changes the task from answer production to evidence exposure. The model has to enumerate the weekdays, inspect the relevant property, and make the hidden operation visible. Once the check becomes explicit, the error collapses.
That is the smallest possible evidence loop.
The scale is ridiculous: seven words, one letter, one universal suffix. The pattern is serious. A generated answer can appear before the operation that would justify the answer has actually been performed. Fluency arrives before proof. Confidence arrives before inspection. The artifact looks complete because the surface is complete.
Software generation has the same shape, but with higher consequences.
In one sense, code generation is easier for a language model than counting letters. Code has semantic gravity. APIs, parsers, handlers, schemas, migrations, clients, controllers, test harnesses, build systems, and integrations all have learned shape. The model can generate useful software because software is full of conventions, patterns, adjacent examples, and recurring structures. It can move through that space with extraordinary speed.
Correct software, however, is exact. A parser rejects malformed input or it accepts it. A migration preserves the invariant or corrupts it. A public interface remains compatible or breaks callers. A security boundary holds or leaks. A failure mode is observable or invisible. At the point where software becomes part of production reality, plausibility has no authority.
This is where immature AI adoption creates debt. The machine generates artifacts faster than the organization can absorb them: code, scripts, dashboards, tests, internal tools, integrations, prompt chains, operational glue. Some of that work is valuable. Some is wrong. The dangerous category is the middle: plausible enough to keep, insufficiently proven to trust.
That is the inventory phase at the smallest scale.
A generated artifact becomes inventory when it enters the system before it has earned its place there. At first it is a helper, a prototype, a temporary dashboard, a migration script, a wrapper, a workflow, or a convenient internal tool. Then it acquires callers, users, permissions, routines, alerts, dependencies, undocumented behavior, and social weight. When the proof loop finally arrives, the artifact is no longer isolated. Refactoring now has to preserve accidental behavior, negotiate ownership, and unwind assumptions nobody deliberately approved.
That is how AI-generated work becomes technical debt. The issue is broader than bad code. Generation and absorption are different activities. Generation produces an artifact. Absorption determines whether the artifact belongs, whether it composes with the surrounding system, whether its boundaries are stable, whether its failure modes are understood, whether it can be operated, whether somebody owns it, and whether it can be removed. AI accelerates generation dramatically. Absorption remains a coordination problem.
The weekday example demonstrates the missing transition. The first answers were generated claims. The proven answer was constrained by visible evidence. For a word question, evidence is enumeration. For software, evidence is contracts, examples, regression tests, fuzzing, integration checks, type boundaries, security constraints, observability, rollback behavior, operational runbooks, and explicit failure cases. The exact proof surface depends on risk, but the structural requirement stays the same: generated work must pass through evidence before it becomes production inventory.
This also clarifies the right control surface for AI-assisted engineering. Line-by-line micromanagement wastes human judgment on machine-speed detail. The better pattern is closer to mission command: preserve this contract, keep this interface stable, reject these malformed inputs, maintain this latency envelope, expose this failure mode, keep the wire format unchanged, and prove the result. The human defines intent, constraints, boundaries, and evidence requirements. The machine performs tactical execution. The system treats execution as incomplete until the evidence exists.
That is the Coordination Shift under a microscope. When execution becomes cheap, the bottleneck moves away from producing more artifacts and toward governing what production means. The scarce work becomes judgment, verification, coherence, ownership, interface quality, operational fit, and absorption. The human role moves with the bottleneck: less typing of implementation detail, more definition of intent, risk, boundaries, taste, and proof standards.
The weekday failure is useful because it strips the problem down to its smallest form. There is no architecture, no organizational politics, no dependency graph, no legacy system, no stakeholder pressure, no release train. There is only a generated answer and a tiny proof loop. Once that distinction is visible at the scale of seven weekday names, the same pattern is easier to recognize in a generated service, integration, test suite, dashboard, workflow, or operational tool.
The lesson is blunt: fluency is not proof.
AI-assisted software development becomes dangerous when an organization confuses generated output with absorbed capability. More code does not automatically mean progress. More automation does not automatically mean leverage. More generated tests do not automatically mean evidence. More internal tools do not automatically mean capacity. Without proof loops, the organization accumulates future refactoring work at machine speed.
The answer is to keep generating, but to make generated work prove its right to remain.
That is the proof loop.
Small enough to explain with weekday names.
Large enough to govern the next phase of software production.